An Essence of Data Modelling
Nov 18, 2021
This talk was delivered for dbt Labs on behalf of Tier Mobility GmbH in Berlin, Germany, on November 18, 2021.
The video is available in full on YouTube below:
1. Introduction
Navigating the complexities of Analytic Engineering often feels like venturing into a vast ocean of unstructured data. Sometimes we’re armed with a map, but more often than not, we find ourselves without clear guidance, tasked with the challenge of bringing order and clarity to a chaotic data landscape. In this talk, I aim to share some of the insights, strategies, and practices in data modeling that I’ve accumulated along my journey.
My path into the world of data started much like many of you listening today. I was captivated by the prospect of making predictions, which naturally led me to assemble large datasets, often wrestling with substantial volumes of data sourced from places like Wikipedia and other public domains. I spent some time studying statistics and then found myself in Berlin. Here, I honed my skills in SQL, dbt, and the foundational aspects of data modeling.
Before diving in, I want to emphasize that what I’m about to share are personal insights gained from my experiences in the analytics ecosystem. These methods have served me well, both individually and in team settings, enabling me to construct scalable and maintainable data warehouses and transformation pipelines. I don’t claim to be an expert in dbt or SQL, but I am eager to share my learnings with aspiring analytic engineers. This field is as much an art as it is a science, and there’s often more than one solution to any given problem. So, if you have alternative approaches or insights, I’m all ears.

Let’s start by defining what we mean by ‘data modeling’ within the context of analytic engineering and dbt. In the broad spectrum of data-related fields, ‘data modeling’ can take on various meanings. For data scientists and machine learning engineers, it often involves statistical modeling techniques such as linear and logistic regression, k-means clustering, xgboost, or principal component analysis.
In this talk, however, when I refer to data modeling, I’m speaking about the transformational steps that occur after the raw data has been Extracted and Loaded into a Data Warehouse (DWH). I’m focusing on the ELT (Extract, Load, Transform) approach, as opposed to the traditional ETL (Extract, Transform, Load) paradigm. These transformation steps involve converting raw tables or events into standardised formats that are more accessible and manageable for end-users. These users range from other analytic engineers, data analysts, and machine learning engineers to business analysts and even non-technical stakeholders. The goal is to create models that represent a refined, distilled essence of the data, facilitating more straightforward and effective insight derivation, and catering to tools like Looker or Power BI.
2. A Generalised Structure of Transformation layers
In this section, I will provide a brief overview of the ELT (Extract, Load, Transform) stack we utilize at Tier. You might be familiar with some elements of this stack, but I’ll walk you through each layer to give you a comprehensive understanding.
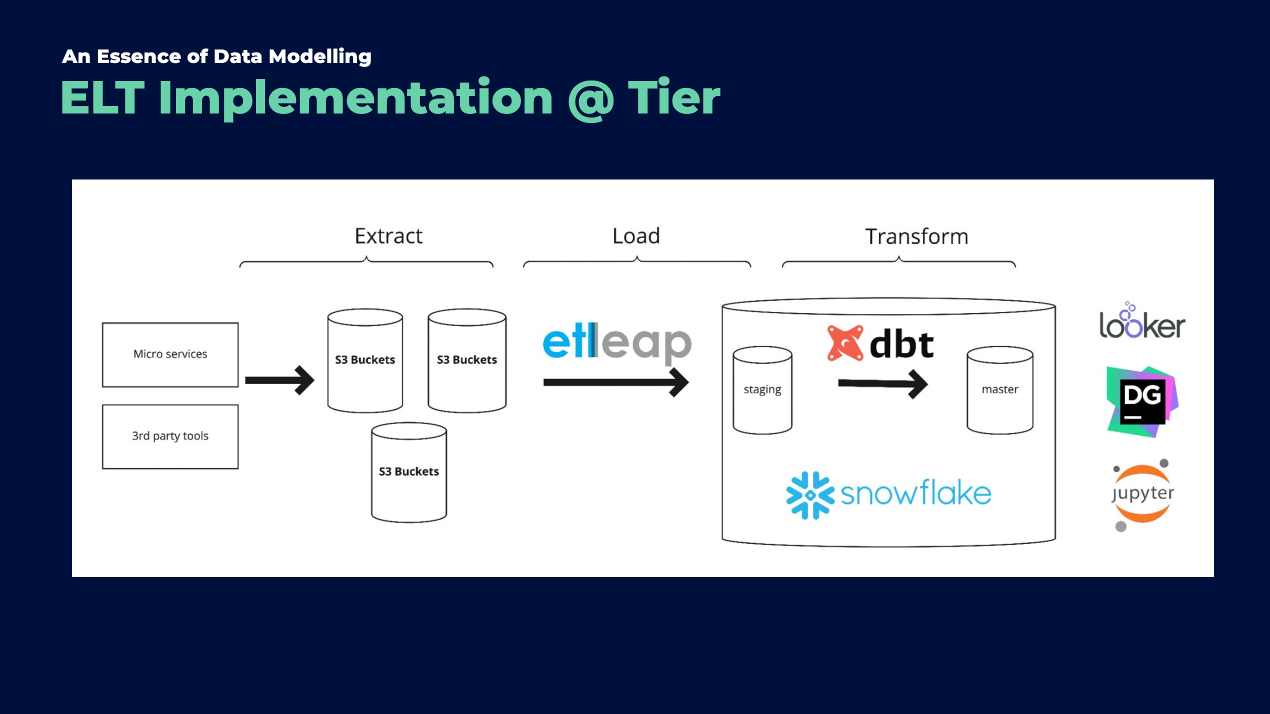
2.1 Source
Our data sourcing encompasses a blend of internal and external inputs. Internally, we gather data from various microservices linked to the product side of our company. Externally, we incorporate data from third-party tools such as Segment and Freshdesk. Currently, our primary extraction method involves pulling data from S3 buckets. However, we are in the process of transitioning to Kafka for more direct event ingestion.
2.2 Loading
The data from S3 buckets is loaded into our Data Warehouse (DWH) on Snowflake via Etleap. This stage is crucial as it involves the initial processing of raw JSON files, which includes flattening the data structure and performing basic transformations like type casting, formatting, and standardisation.
2.3 Transformation
This is where we delve into the core of our process: the transformation stage, leveraging the capabilities of dbt. At this stage, we transform raw tables into a structured network of models aimed at providing functional tables for insightful data analysis.
Maintaining a consistent segregation of models is key. It allows our analytic engineers to categorize different models effectively and provides a structured framework for integrating new models.
2.4 Consumption Layers
Our master schema or core models form the foundation for data exposure to tools like Looker and are essential for our data scientists’ work. These core models are typically structured as Fact and Dimension tables. Dimension tables are exhaustive lists of entities (like customers, suppliers, or vehicles), while Fact tables document recurring events (like orders, rentals, or page views).
A useful analogy is to think of Dimension tables as listing ‘nouns’ and Fact tables as containing ‘verbs’. Alternatively, you could view Fact tables as narrating a story, with Dimension tables serving as the table of contents.
2.5 Data Marts
Data marts represent a further refined layer of our data structure. These are tables that contain aggregated data, often embedding business logic and undergoing significant, computationally intensive transformations. An example in our context is a sessions table, which catalogs individual user sessions on a webpage or app. At Tier, one specific data mart project involves modeling scooter idle time – a complex task that I’ve personally found quite challenging and instructive.
3. Utilising CTEs in Data Modeling
In the realm of data modeling, we often transition from broader models to the more detailed realm of Common Table Expressions (CTEs). CTEs serve as modular select statements, essentially acting as building blocks within the larger structure of a model. I like to think of them as ‘micro-models’ within the overarching ‘macro-model’.

3.1 The Role and Structure of CTEs
A CTE is designed to perform a singular, focused task. This could range from applying a similar transformation to a set of fields, filtering specific rows, or adding a new field that becomes integral in subsequent CTEs. The key is to maintain clarity and simplicity within each CTE, ensuring that each one contributes meaningfully to the model’s overall objective.
3.2 Naming and Organizing CTEs
Clarity in naming is crucial. Each CTE should have a descriptive alias or label that succinctly conveys its function. For example, a CTE designed to eliminate duplicate records might be aptly named remove_duplicates. This approach not only aids in readability but also in the maintainability of the model.
3.3 Efficient Column Selection
When it comes to selecting columns within a CTE, efficiency is paramount. After defining the essential fields derived from prerequisite models, it’s often unnecessary to explicitly list each column again. In such cases, utilizing the * wildcard is a practical approach. This technique selects all columns without the need to enumerate them individually, streamlining the process.
The positioning of newly created fields within a CTE is largely a matter of personal preference, though it can have practical implications. I generally place the * at the bottom of the CTE, which results in the newly created fields appearing at the beginning of the output. This positioning is particularly helpful during the testing phase, as it saves the effort of scrolling to the far right to inspect the newly created fields.
Conversely, some prefer to list the * first, positioning the new fields at the end of the output. This method has its merits as well, especially in terms of consistency with the original data structure. Ultimately, the choice depends on individual workflow and the specific requirements of the project.
4. Mortal sins: nesting queries.
In the realm of data modeling, the use of nested queries is a topic that often invites debate. My stance on this is relatively straightforward: I generally advise against incorporating nested queries within models. While nested queries, which are select statements embedded within another select statement (typically in the from clause), can sometimes offer elegant solutions, they are less ideal in a collaborative team environment. This is especially true when multiple analytic engineers are involved in maintaining a complex Data Warehouse filled with various models.
4.1 Advantages of a Linear Flow
I advocate for a linear flow in data models, mirroring the straightforward progression we find in written text. This approach not only simplifies the understanding of each common table expression (CTE) and its output but also clarifies how these CTEs interlink to culminate in the final model. A linear, unidirectional structure in data modeling facilitates easier assessment and maintenance.
4.2 Structuring CTEs for Clarity and Flexibility
When it comes to writing CTEs, I prefer a specific formatting style that enhances readability and ease of testing. I place the comma, the alias, the ‘as’ keyword, and the opening bracket all on the same line, as follows:
,customers as (
This format offers practical advantages during the building, testing, and debugging phases of a model. For instance, one can swiftly comment out the line mentioned above and select the code from the end of the CTE to its beginning to run a test. This methodology has been particularly beneficial in the initial stages of model development, allowing for efficient troubleshooting and verification of individual CTEs.
4.3 Simplifying the Final Selection
The concluding line of the model, typically a select * from final, is structured to enable effortless substitution with another CTE within your model. By doing this, when you run the model, it immediately displays the result of the specified CTE. This flexibility is instrumental in refining and adjusting the model during its development stages, ensuring that each part functions as intended before integrating it into the larger whole.
5. Happy families are all alike
In the landscape of data modeling, the concept of developing ‘families’ of interrelated models is far more advantageous than creating isolated models. This approach fosters consistency in results and reduces maintenance overhead, as each model in the family works in tandem with the others. For instance, a modification in an upstream model naturally cascades into the downstream models.
The benefit here is a potential reduction in maintenance workload for analytic engineers. It’s less juggling multiple spinning plates and more like tinkering with a finely-tuned engine.
However, this methodology does come with its challenges. Adding new fields to upstream models requires careful consideration to avoid issues like record duplication or inaccurate aggregations in downstream models or visualizations.
This interdependence might not always be immediately evident and can often be recognised only after spending time working within a single codebase. Regular team assessments are crucial to determine if components within models can be restructured or repurposed. Additionally, when creating new models, it’s beneficial to first consider leveraging existing models that may already perform some of the required computations.
6. Words, words, words: Renaming columns
When it comes to renaming columns during the transformation process, I recommend minimal alteration from their original names in source tables. Ideally, renaming should be reserved for the final core model that will be presented to stakeholders or used in data tools like Looker or PowerBI.
Maintaining consistency in column names across transformation steps greatly eases the workload for analytic engineers who may need to join tables or navigate the Data Warehouse. While it may be tempting to rename columns for user-friendliness, this can often lead to confusion and further abstraction.
Many of us have experienced the frustration of searching for a field, only to discover it was renamed to something less intuitive.
7. Git it? Got it. Good
Git and GitHub play a pivotal role in software development, and their importance extends to building data models with dbt. Fully integrating the code review process, which involves pushing to a branch and then merging into the master branch, is crucial. This practice is essential for validating models, identifying errors before they reach production, and facilitating knowledge sharing within the team. It’s particularly valuable for junior team members to learn from their more experienced colleagues.
A few comments on setting style guides. It’s not the most exciting topic, but having a consistent team coding style is very important.
On the topic of setting style guides: while it may not be the most exhilarating subject, establishing a consistent team coding style is vital. This balance between individual preferences and team norms should be determined by the Analytic Engineers responsible for building and maintaining the transformation pipelines and core models. The choice between using uppercase or lowercase in SQL statements, for instance, is less important than achieving uniformity.
If your team has access to automatic code formatting tools, I highly encourage their use to maintain this consistency.
8. A brief interlude into my workflow
This section provides a snapshot of my workflow in data modeling. It’s important to note that these steps often overlap and are not strictly sequential. Flexibility is key, as I may revisit previous stages when new insights or requirements emerge.
8.1 Research
The initial stage involves engaging with stakeholders to ascertain the required data. This phase is critical for grasping the internal processes that generate this data, as well as identifying subtle nuances that might influence the final model.
8.2 Planning
During the planning phase, I conceptualize the model’s structure, determining the necessary columns and the extent of data aggregation. This stage also involves deciding on any requisite filters. For complex models, particularly those integrating multiple sub-models and/or CTEs, I typically sketch out the overarching workflows to maintain clarity.
8.3 Exploration
This stage primarily revolves around searching the Data Warehouse for the required data. Occasionally, if the data isn’t already present in the Data Warehouse, it necessitates creating new pipelines. Exploration is crucial for discovering whether the data is already in an existing model. In large corporations with large Data Warehouses and many data experts, it may require some research to look through the models and read documentation. The objective is to avoid duplicating an existing model, since this will lead to confusion downstream and add to the technical debt of the Data team.
8.4 Scratch Building
I usually start building the model in a SQL Runner IDE, such as Dbeaver, constructing one CTE at a time. If there is a large amount of data, I will filter the initial CTEs for one particular customer id or vehicle id, so that the model has many events across time in which to assess the transformations that will apply in each CTE. This approach ensures that the model remains efficient as it evolves.
8.5 Into VS Code
Once the model has progressed to a point where I have the rough output I want, I move the model to VS Code. This involves creating a new branch in our dbt repository and placing the model within an appropriate directory. At this juncture, I also integrate dbt-specific coding elements necessary for building the table in the Data Warehouse.
8.6 Incremental logic
If the amount of data is quite large, I will then add incremental logic to the model.
8.7 Test dbt run in CLI
The next step involves testing the model in my local schema to ensure its successful creation. Depending on the data size, I might initially apply a filter to a specific customer or vehicle. This filter is only for testing and will be removed in the final model.
8.8 Testing output
The final stage is dedicated to meticulously verifying the accuracy of the model’s data. This involves checking distinct counts, validating timestamps, and ensuring that monthly summations align with previous models or the insights provided by other business stakeholders. Thorough testing is both an art and a necessity, aiming to cover as many aspects as possible to ensure data integrity.
Concluding Reflections: Insights and Guiding Principles
As we approach the conclusion of this discussion, I would like to offer some guiding principles and insights that have shaped my approach to model building. These are not just mere suggestions, but foundational concepts that have consistently proven their value in my experience.
Continuous Learning through Observation: One of the most effective ways to enhance your skills is by observing and learning from the modeling techniques of others. Different perspectives can offer fresh insights and innovative approaches.
Pursuit of Efficiency and Clarity: In my journey, I am perpetually in search of methods that not only simplify the expression of a model but also enhance its efficiency. The quest for improvement is ongoing and ever-evolving.
Embracing Multiple Pathways: There is no singular, definitive way to build a model. Each project is a unique journey, often filled with complexities. Recognize that striving for an ideal model is a process fraught with challenges and learning opportunities.
The Importance of Sequential Building: I advocate for a methodical approach to model construction – building it one component at a time. This approach allows for thoughtful development and the flexibility to revisit and refine earlier stages as needed.
Robustness over Complexity: In my experience, models that prioritize robustness and reliability tend to outperform those with overly intricate and fragile structures. Simplicity and strength often go hand-in-hand in creating durable models.
Self-Compassion in the Process: Lastly, it’s crucial to remember that the pursuit of perfection, especially in the initial stages of model building, is not just impractical but can be counterproductive. Be patient and kind to yourself; excellence in modeling is achieved over time and with experience, not overnight.